Annotate from Database allows you to annotate your sequence with particular genes or motifs from a custom annotation database. This function uses a BLAST-like algorithm to search for annotations in the Source folder that match your sequence, by aligning it against the full length of each annotation. Annotations which match with the given similarity are copied to your sequence.
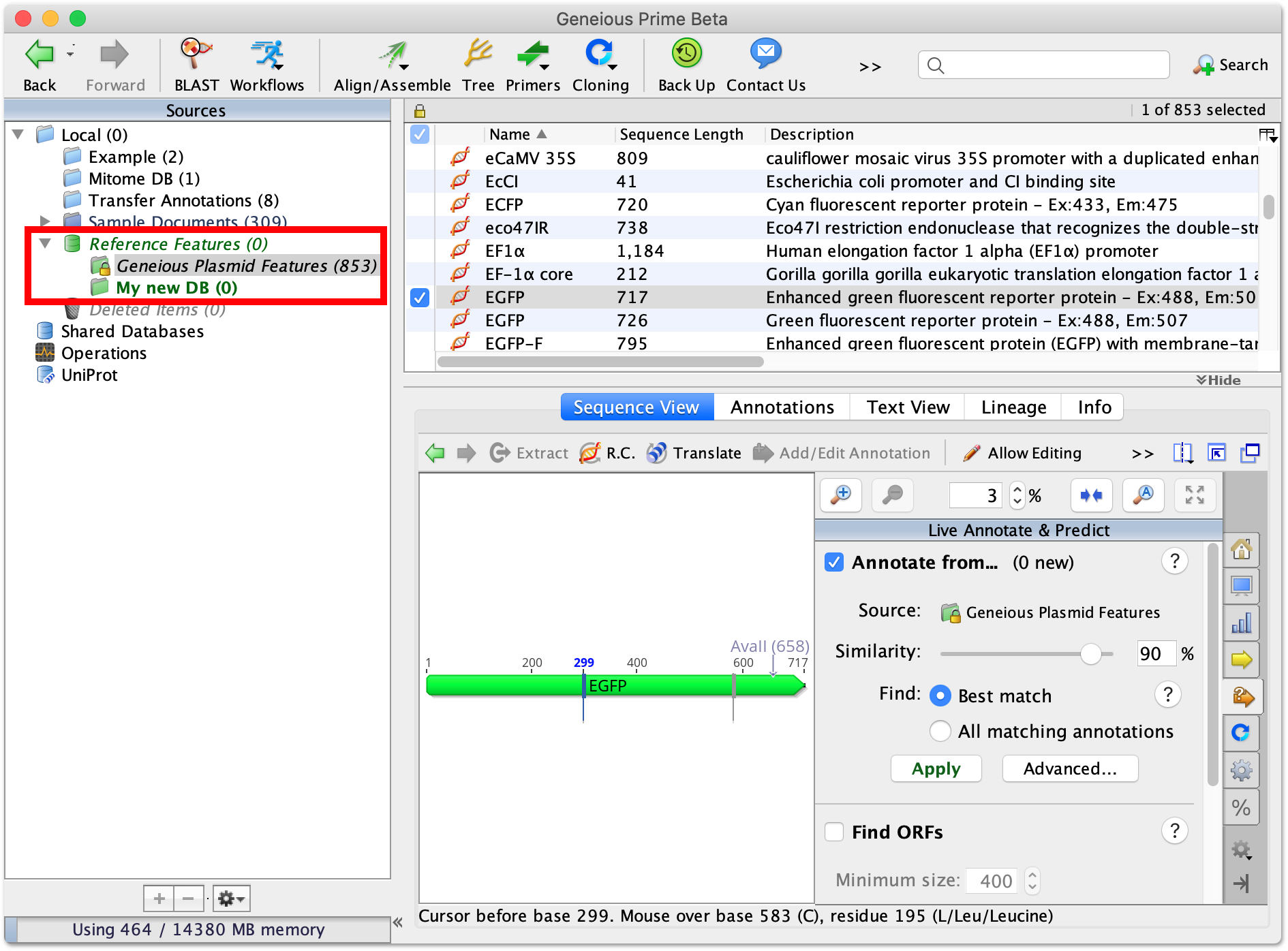
To use Annotate from Database, click the ![]() Live annotate and Predict tab to the right of the viewer, and check the Annotate From... box. Then set the Source folder you wish to use to annotate your sequences.
Live annotate and Predict tab to the right of the viewer, and check the Annotate From... box. Then set the Source folder you wish to use to annotate your sequences.
The default Source annotation folder is the Reference Features folder which can be found at the bottom of your Local folder (see Figure 8.6 ). Within this is a locked Geneious Plasmid Features folder which contains a curated list of common plasmid features including promoters, terminators, tags, rep origins and marker genes.
You can also create a customized annotation database from other sequences in your database. These sequences can be annotated or unannotated nucleotide or protein sequences, such as reference genomes downloaded from Genbank, lists of peptides, BLAST hits, or your own previously annotated sequences. These sequences should be placed in their own folder, which can then be selected as the Source to annotate from. You can set any folder within your database as the Source folder, but we recommend you place your personal annotation databases in the Reference Features folder so they are easy to find and access.
You may need to adjust the Similarity slider in order to find matches between your sequence and the source annotations. This sets the minimum percentage of sites covered by an annotation that must be identical in order to transfer the annotation. Insertions and deletions count as mismatched sites. Ambiguous matches are counted as partial mismatches. For example, for nucleotides, N versus A is 0.75 of a mismatch. Similarity is calculated along the full length of the annotation. For example, if your sequence is only half the length of the annotation, it can have a maximum similarity of 50%.
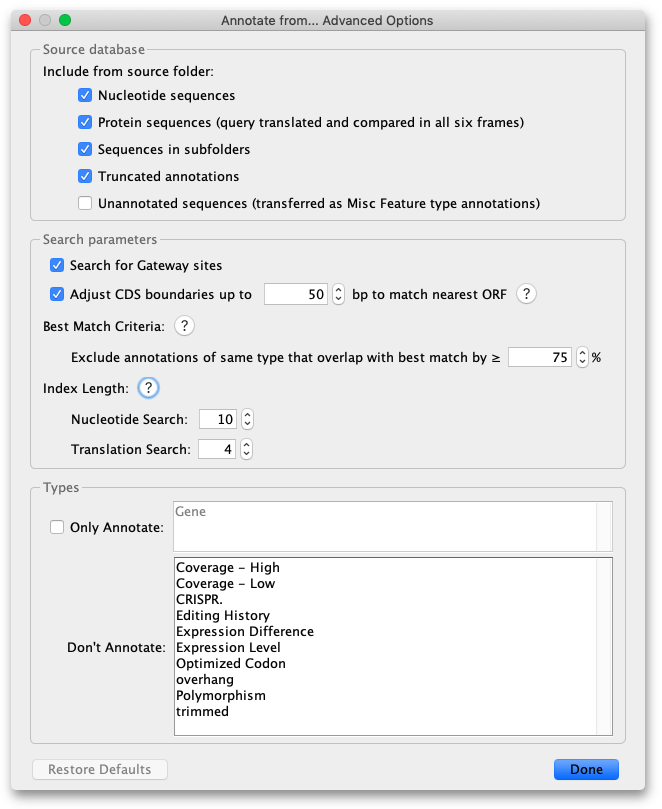
By default, only the Best match annotation will be shown in cases where multiple annotations of the same type overlap with each other in the same region on the target sequence. The best match is considered as the annotation with the highest similarity at a position, when comparing annotations of the same type that overlap in length by the % threshold set in the Advanced options under Best Match Criteria (default is 75% length overlap). The exception to this is primer annotations, where all annotations are always annotated.
To turn off this behaviour and annotate all annotations, choose All matching annotations.
Once you are happy with how your annotations look, click Apply to add them to the sequence. If you only want to add a selected few of the annotations that are previewed on the sequence, select those annotations you want to add before clicking Apply.
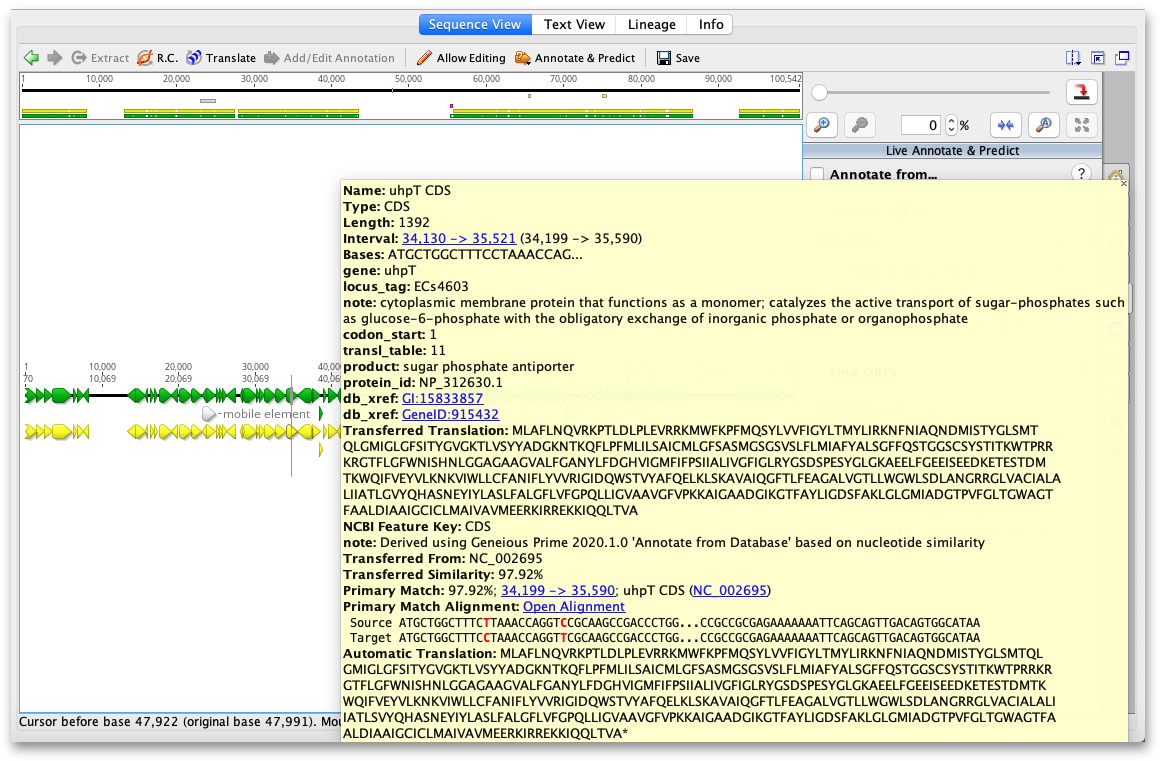
The transferred annotations contain the annotation qualifiers from the original sequence (note that some of these, such as database references and transferred translation may not be correct for the target sequence), plus qualifiers detailing the source of the transferred annotation and the match percentage (See Figure 8.7 ). The Open Alignment hyperlink allows you to view an alignment of the target region and matching annotation.
Annotating nucleotide from protein sequences.
Nucleotide query sequences can be annotated from protein or nucleotide source sequences. If annotating from protein, the nucleotide query will be translated in all 6 frames for comparison to the protein sequences. You can disable this option by unchecking Protein sequences under the Source database advanced options.
Using unannotated sequences in the Source folder
You can optionally annotate from unannotated sequences in your Source folder. Geneious will treat sequences without any annotations as though they have an annotation of type ”misc feature” which covers the full length of the sequence and is named the same as the sequence name. If a match is found, this ”misc feature” annotation will be transferred to the query sequence. To turn on this option, check Unannotated sequences (transferred as Misc Feature type annotations) under the Source database advanced options. When this option is off, unannotated sequences will be ignored.
Adjusting the search parameters